概要
簡単に使える Pure JavaScript の形態素解析器 kuromoji.js を書きました。今回は、簡単に kuromoji.js を紹介したあと、セットアップ方法を解説します。ついでにロードマップ的なものも晒してみます。みんなでブラウザ NLP しよう!kuromoji.js とは
言わずと知れた Java の形態素解析器 Kuromoji を JavaScript に移植したものです。kuromoji.js の GitHub リポジトリ
と言っても、機械的に Java から JavaScript に置き換えたものではないため、API も違いますし、メソッド名やその内部も大幅に異なります。そもそも自分が形態素解析について勉強するために書き始めたため機械的なトランスレートに興味がなかったこと、また言語ごとに使いやすい API は異なると考えていることが理由です。
Node.js ではもちろん、ブラウザでも動作します。ブラウザで形態素解析することのメリットについては、あんちべさんのブログが参考になります。
RakutenMAによる形態素解析入門 - あんちべ!
ただ、内部で TypedArray を使用しているため、IE8/9では、そのままでは動作しないと思います。TypedArray の polyfill を使えば動くかもしれません。
npm や bower といったパッケージマネージャを使って、リポジトリからサーバや開発環境に簡単にインストールすることができます。
ライセンスは Apache-2.0 です。現在の kuromoji.js は、MeCab に付属している IPADIC という辞書を使っています。
Kuromoji の開発元は Atilika という会社です(現在はソースコードは Apache Software Foundation に寄贈されています)。ちなみに、kuromoji.js は Kuromoji の公式な JavaScript ポーティングとなったので、そのうち Atilika のページからリンクが張られるはずです。
形態素解析ってなに?
「百聞は一見に如かず」ということで、以下の kuromoji.js のデモサイトにアクセスしてみてください。17MB くらいある辞書がダウンロードされるので、太い回線で試してください。kuromoji.js のデモサイト
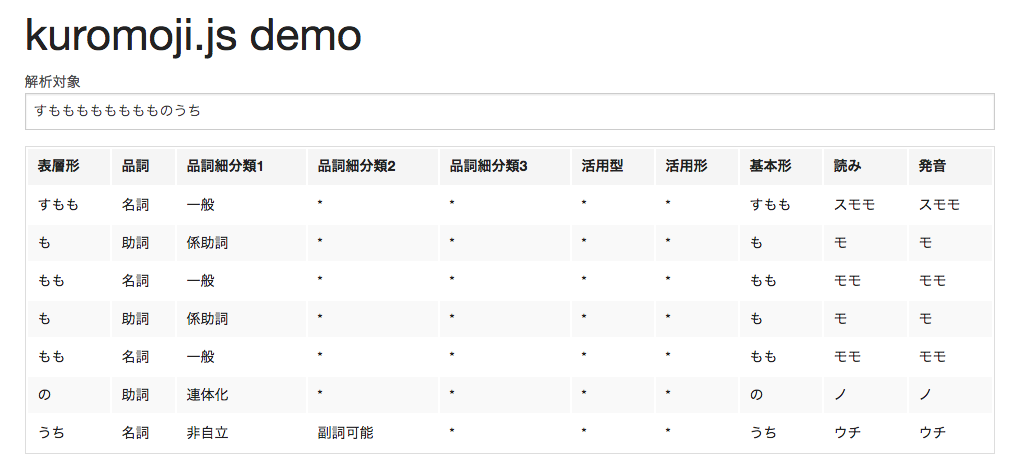
「すもももももももものうち」という文が、形態素解析された結果が表示されたでしょうか?
形態素解析とは要するに、上記の「辞書」に基づいて、単語的なもの(形態素)に分解し、品詞や読み、基本形などを付与する処理のことです。
身近な例でいうと、Google などの検索エンジンをはじめ、Siri などの音声認識や、IME(かな漢字変換)でも同様の技術が使われています。他にも、テキストマイニングや、ニュース記事のレコメンド(SmartNews が有名ですね!)などへの応用もあります。形態素解析は、日本語を日本語としてコンピュータで扱うときに必須とも言える、非常に重要な基礎技術です。
なお、「形態素」という言葉の定義は、立場によって異なるので、注意が必要です。品詞体系によっても異なるので、同じ形態素解析器でも辞書(IPADIC とか Unidic とか)を変えると挙動が違ってきます。
使い方
上記のデモサイトと同じデモサーバを、各自のローカルマシンで起動する手順を説明します。これにより、kuromoji.js を使った Web アプリの開発環境をさくっとセットアップすることができます。
ブラウザで使うために kuromoji.js のパッケージを落としてくるには
bower install kuromoji (node.js で使う場合は npm install kuromoji)を実行するだけなのですが、ローカルで Web サーバを立てたりするのが意外と面倒くさいです。そこで、
gulp と gulp-webserver という便利ツールを使います。これらを組み合わせることで、複雑な手順なしで Web サーバを構築することができます。あとは、demo/ の下の HTML や JS などを自由に書き換えることで、kuromoji.js を使った Web アプリケーションのフロントエンドを自由に開発できます(デモページではフレームワークとして Vue.js を採用していますが、お好きなものをお使いください)。また、デフォルトでページの自動更新 (livereload) が有効になるように設定されていますので、HTML や JS ファイルを修正する際のデバッグがとても楽です。ぜひ試してみてください。
インストール
まず、Node.js と Git をインストールしておいてください。Windows 環境では Chocolatey、Mac なら Homebrew を使うのが便利でしょう。
次に
npm で、gulp と bower をグローバルインストールします(いずれも、すでに入っていたら不要です)。$ npm install -g gulp依存パッケージのインストール
$ npm install -g bower
作業ディレクトリに移動したら、
git clone して、そのプロジェクトルートで npm install コマンドを実行します。すると、package.json の内容に従って、kuromoji.js の依存パッケージがダウンロード・インストールされます。以下に手順を示します。$ git clone https://github.com/takuyaa/kuromoji.js.gitデモサーバで必要になる、bower の依存パッケージをインストールします。パッケージ(kuromoji.js 含む)は、 demo/bower_components/ 以下にインストールされます。
$ cd kuromoji.js
$ npm install
$ cd demoデモサーバの起動
$ bower install
gulp-webserver を起動します。プロジェクトルートに移動して、gulp の webserver タスク(後述)を実行すると、8000 番ポートで Web サーバが立ち上がります(ポート番号を変更したい場合は kuromoji.js のプロジェクトルートにある gulpfile.js を編集してください)。$ cd ..これで準備完了です。
$ gulp webserver
(ただ FireFox だと JS でエラーが出るので、 Chrome か Safari で試してください…すみません…)
demo/ の下のファイルを編集すると、ブラウザの画面が自動的にリロードされるはずです。Have fun!
タスク実行(ビルド・テスト等)
先ほどから何回か出てきた Gulp とは、いわゆるタスクランナーというものです。さっきはwebserver タスクを実行しましたが、 kuromoji.js には他にも様々なタスクが定義されています。- clean (dist/ の下をきれいにする)
- build (ソースから browserify したファイルを dist/browser/ の下に置く(ブラウザ版)。またはコピーして dist/node/ の下に置く(Node.js 版))
- watch (ソースの変更監視。変更されたら lint, build, jsdoc タスクを実行)
- clean-dict (dist/dict/ の下をきれいにする)
- build-dict (CSV の辞書ファイルからバイナリ辞書を構築する)
- test (mocha でテストを実行する)
- coverage (coverage/ 以下に Istanbul でカバレッジ計測した結果を出力する)
- lint (jshint でコードの静的チェックを行う)
- webserver (デモサーバを立ち上げる(上述))
- jsdoc (jsdoc/ 以下に JSDoc を出力する)
$ gulp build-dictを実行することで、kuromoji.js で使用される、各種バイナリ辞書がビルドできます。後述しますが、ユーザ辞書機能がまだありません。単語を辞書に追加する際には、CSV のシステム辞書に単語生成コストや文脈IDなどと共に行を追加して、丸ごとビルドしなおす必要があります(環境にもよりますが 1 分程度でしょうか)。
なお、
gulpfile.js のベストプラクティスがあまりよく分かってないので、本当はストリームとか使って、もっと効率的に書けると思います(誰か教えてください…)。今後サポートしていきたい機能
- ユーザ辞書
- Search モード
- NAIST-jdic, Unidic のサポート
- 辞書サイズの低減
- N-best 解の出力
- kuromoji-server(形態素解析 Microservice)
- Stream サポート
学習コーパスを追加することによる、再学習機能の要望も頂いていますが…まず CRF を JavaScript で実装しないといけなかったりして、相当大変そうです(パーセプトロンを JS で実装してみた感じからすると、不可能ではないと思いますが…)。ちなみに、同様のことを実現するには、MeCab で辞書を再学習させ、学習済み CSV を scripts/input/ に置いて、上述の
gulp build-dict でバイナリ辞書をビルドすれば可能だと思います。誰か試してブログ書いてくれないかなー(チラッチラッSearch モードは、Kuromoji (Java) を特徴づける機能で、出力される形態素を、より小さくなるようにするモードです。形態素列が、より短い単語列になるように、ラティス上の接続コストを調整します。たとえば、検索エンジンで形態素解析器を利用する際、Recall を上げるためにトークンを細かくするというチューニングがしばしば行われます。そういった場合に有用となるモードです。なお、Kuromoji (Java) には、Search モードの機能に加えて、未知語を Uni-gram (1文字ずつ)に分解する Extended モードもあります。
NAIST-jdic, Unidic のサポートは、辞書に IPADIC 以外の選択肢を与えるものです。それぞれ特性があるので、用途によって使い分けます。Unidic は細かい形態素に分かれやすいという特徴があるので、検索エンジンのトークナイザ用途に向いているという話もあります(その分、転置インデックスのポスティングリストは長くなるので遅くなりますが)。
辞書サイズの低減に関しては、用途によっては不要な Feature を削った辞書、というのをサポートすることで、辞書サイズを多少減らせます。品詞、文脈ID、生起コストなどは削れないのですが、それ以降の読み・基本形などは、分かち書きだけしたいような場合には不要です。5MB以下まで小さくできれば、ほとんどのブラウザで許可なしでキャッシュできるので、2回目以降は辞書をダウンロードせずにすみます。また、見出し語を格納している辞書(base.dat, check.dat)についても、現在は Double-Array Trie というトライ木の一種を使っていますが、Minimal Acyclic Subsequential Transducer という FST の一種を使うことで、サイズを 1/10 くらいにできるという報告を聞いています。FST の実装については、Go で FST を書いた @ikawaha さんのエントリが参考になります。実装手法も面白いので、ぜひ fst.js を実装してみたいと思っています。
Go - Luceneで使われてるFSTを実装してみた(正規表現マッチ:VMアプローチへの招待) - Qiita
N-best 解の出力というのは、上位 N (任意の自然数)の形態素列の候補を順番に出力することです。kuromoji.js を使って IME を実装する際に必要になってくる機能です。様々なブラウザ上で(端末へのインストールなしで)高精度な日本語 IME が使えるようになる日が来るかもしれません。実装上は、Viterbi の前向きアルゴリズムのときに N 個までの候補を残すようにする、ビーム幅 N の Beam search をするだけです。当然、ビーム幅を増やしただけメモリをたくさん消費します。MeCab にはありますが、Kuromoji (Java) にはない機能です。
kuromoji-server と書いたのは、kuromoji.js を REST API でラップし、Web サーバ化するものです。これにより、形態素解析 Microservice (機能ごとに Web サーバを立てて HTTP 等で通信させ、全体を疎結合にするアーキテクチャ)なサーバを簡単に立ち上げられるようになります。kuromoji.js とは別の GitHub リポジトリになると思います。ただ、Kuromoji (Java) にも同様の kuromoji-server がありますし、Go で書かれた形態素解析器 Kagome には、Web サーバ機能が初めから組み込まれていますので、kuromoji.js で後述の Stream がサポートされるまでは、あまり存在意義がないかもしれません。
Stream サポートは、読んで字の通りで、kuromoji.js に対して文字列の代わりに Stream を与えることで、形態素の Stream を出力するための API を提供するものです。例えば、上記の kuromoji-server に対して、Twitter のストリームを流し込むと、形態素のストリームが出てくるので、それを Spark などの機械学習フレームワークに流し込む、といったユースケースが考えられます。ただ、内部的にかなり手を入れないといけないし、Node.js 側でもブラウザ側でも API がまだ stable ではないため、少し様子見かな…
あとは、高速化できるところが結構あるので何とかしたいです。。doublearray.js を作るときに、サロゲートペアの処理が嫌で(JavaScript の文字コードは UTF-16)、辞書は UTF-8 で保存するようにしてしまったんですが、そのために lookup のたび 1 バイトずつ見て UTF-8 から UTF-16 に変換する処理が走ってます。初めから UTF-16 で辞書を作っておけば、この変換は無くせます(日本語の場合、UTF-16 の方が辞書サイズも小さくなりますし)。他にも、無駄に parseInt してるようなところとかあって、そこも無くせそうな気がしています。
リファクタ的な観点では、async の代わりに Promise にするとか、オレオレ ByteBuffer をやめて ByteBuffer.js 使うとか、全体を ES6 で書き直して 6to5 でトランスパイルするとか、power-assert 使うとかもしていきたいのですが、かなり先になってしまいそうです(コントリビュートは大歓迎!)
リリース後の反応
kuromoji.js を GitHub リポジトリに公開した後、Twitter でツイートしただけなのに、どこから見つけてきたのか、2週間後くらいに MOONGIFT に取り上げられて(記事の内容については色々言いたいことがありますが…)、はてブでホットエントリに入ったらしく、「なんか kuromoji.js とかいう JavaScript の形態素解析器ができたらしい」みたいな話になっていることを Twitter や知人経由で知りました。MOONGIFT に記事が上がった当日には、実際に何人かのエンジニアの方々が kuromoji.js を試していたようです。
その翌日、TypeScript から簡単に使えるように型定義ファイルが書かれ、それが DefinitelyTyped に登録されました。
https://github.com/borisyankov/DefinitelyTyped/pull/3377
さらに、それと並行して、 kuromoji.js を使った構文解析器が書かれました。
自然言語処理 - kuromoji.js使って構文解析した - Qiita
OSS のスピードすごい。
おわりに
形態素解析は、様々な自然言語処理にとって、必須とも言える基礎技術です。kuromoji.js だけで何か凄いことができるわけではありませんが、ブラウザ上で、より高度な自然言語処理をするときの足がかりとなってくれるはずです。自然言語処理によって Web はもっとインテリジェントにできる、と自分は信じています。
kuromoji.js は、すごく簡単に使える OSS なので、これをきっかけに「自然言語処理って楽しい!」ってなってくれたら幸いです。
みなさんの手で、新しい Web を作っていってください。
Thanks to
- Christian Moen (Atilika Inc.)
- Gaute Lambertsen (Atilika Inc.)
Go 言語で書かれた形態素解析器 Kagome の開発者である @ikawaha さんには、ダブルアレイの実装や、形態素解析器の細かい仕様(未知語処理とか)などについて、一緒に議論をしていただきました(教えられることの方が多かったけど)。Kagome と kuromoji.js は開発時期がほぼ同時だったこともあり、モチベーション的にも助けられました。ありがとうございました。
@taniokah さんは、自分の元上司であり、形態素解析をはじめとする自然言語処理のほか、情報検索、機械学習についても多くのことを学びました。発想の柔軟さにも驚かされることが多く、とても勉強になりました。「Kuromoji って JS で実装できんじゃね?」って言い出したのも確か @taniokah さんだったと記憶しています。今は別々の環境になってしまいましたが、今後ともよろしくお願いいたします。
>http://localhost:8000/tokenize.html
返信削除http://localhost:8000/demo/tokenize.html
になりました〜。gulpのバージョンによって違うのかも。
おっしゃる通り、記述が間違っていました。
削除gulpfile を書き換えたときに URL も同時に変わってしまったためで、 gulp のバージョンにはよらず、この URL でアクセスできると思います。
ご指摘感謝いたします :pray:
このコメントは投稿者によって削除されました。
返信削除Borgata Hotel Casino & Spa Launches In New Jersey
返信削除Borgata 통영 출장샵 Hotel Casino & Spa will soon become the 강릉 출장안마 first 양산 출장샵 resort in New Jersey to launch the "Atlantic City" casino-hotel network. It will 충주 출장안마 add 평택 출장샵